Business Navigating the UAE Tax System: A Guide to Compliance and Efficiency acchat.net February 29, 2024
Business Breaking Ground: Historic Moment as Offshore Wind Farms Illuminate U.S. Grid acchat.net January 4, 2024
Business Navigating the UAE Tax System: A Guide to Compliance and Efficiency Read More acchat.net February 29, 2024
Business Breaking Ground: Historic Moment as Offshore Wind Farms Illuminate U.S. Grid Read More acchat.net January 4, 2024
Medical 2024’s Reigning Champion: The Science-Backed Mediterranean Diet Tops Again, Revealing the Best Diets of the Year Read More acchat.net January 4, 2024
Business 2023, Berjaya Food, Net income, Revenue, Starbucks Berjaya Food’s Triumph and Challenges: Unveiling 1Q Financial Performance in 2024 acchat.net November 16, 2023
Navigating the UAE Tax System: A Guide to Compliance and Efficiency Business Navigating the UAE Tax System: A Guide to Compliance and Efficiency
2024’s Reigning Champion: The Science-Backed Mediterranean Diet Tops Again, Revealing the Best Diets of the Year
Celebrities Transforming: The Inspiring Journeys of Kelly Clarkson, Lainey Wilson, Post Malone, Jesse Plemons, George Conway, and Ana Navarro in Their Weight Loss Success
Chronic wasting disease, deer Unveiling the ‘Zombie Deer Disease’: A Global Challenge at the Human-Wildlife Interface
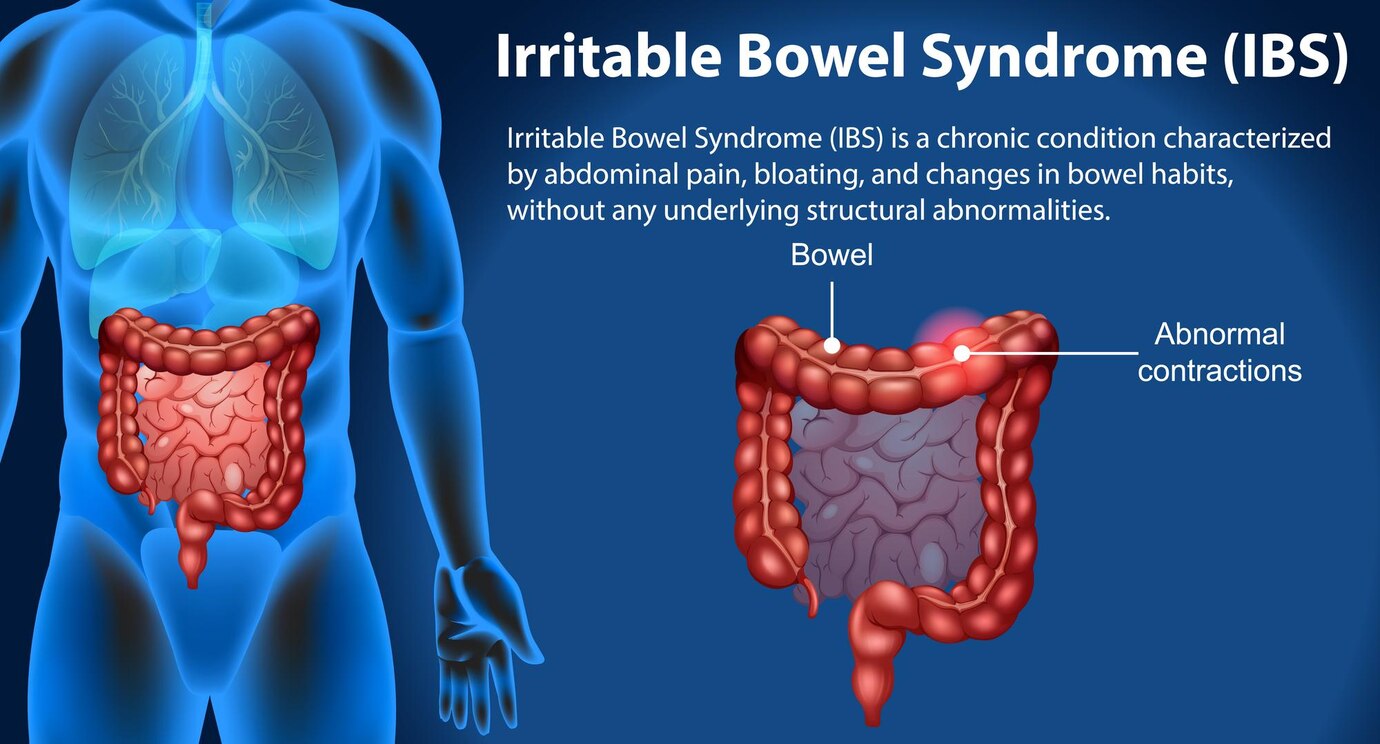
Digestive Health, Gut Disorders, IBS Symptoms Understanding Irritable Bowel Syndrome (IBS): Symptoms, Triggers, and Management
Digestive Disorders, Diverticulitis, Gastrointestinal Health Understanding Diverticulitis: Causes, Symptoms, and Management